
== Use Case ==
== Use Case ==
The primary use case addressed by the proposed system arises from [[Regulatory agency|regulatory and compliance]] requirements imposed by governmental, financial, and industry oversight authorities. Across such regulatory frameworks, a consistent mandate is the maintenance of a complete, immutable, and verifiable audit trail for all user-initiated operations that result in the creation, modification, or deletion of persistent data. These requirements are particularly prominent in domains such as [[Banking regulation and supervision|banking]], healthcare, public administration, and large-scale enterprise systems, where accountability, traceability, and non-repudiation constitute foundational operational principles.
The primary use case addressed by the proposed system arises from [[Regulatory agency|regulatory and compliance]] requirements imposed by governmental, financial, and industry oversight authorities. Across such regulatory frameworks, a consistent mandate is the maintenance of a complete, immutable, and verifiable audit trail for all user-initiated operations that result in the creation, modification, or deletion of persistent data. These requirements are particularly prominent in domains such as [[Banking regulation and supervision|banking]], healthcare, public administration, and large-scale enterprise systems, where accountability, traceability, and non-repudiation constitute foundational operational principles.
A central expectation of these regulatory bodies is that no operation affecting persistent state may obscure, overwrite, or irreversibly eliminate historical information. Instead, every state transition must remain observable and reconstructible throughout the lifetime of the system. Figure~1 presents the high-level use case diagram corresponding to these requirements, illustrating the interaction between system users, the command-processing subsystem, and the auditing infrastructure.
A central expectation of these regulatory bodies is that no operation affecting persistent state may obscure, overwrite, or irreversibly eliminate historical information. Instead, every state transition must remain observable and reconstructible throughout the lifetime of the system. Figure~1 presents the high-level use case diagram corresponding to these requirements, illustrating the interaction between system users, the command-processing subsystem, and the auditing infrastructure.

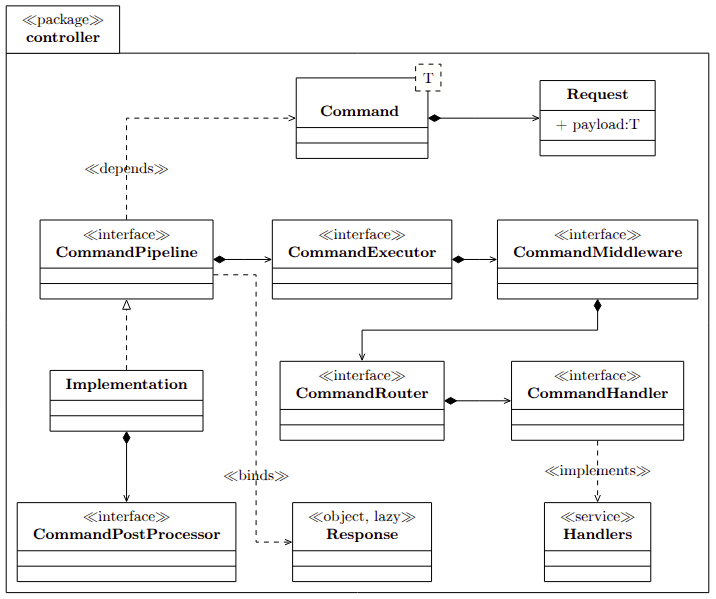
In modern enterprise systems, increasing architectural complexity has introduced significant challenges related to scalability, maintainability, and runtime performance. Implementations of Command Query Responsibility Segregation (CQRS) and event-driven designs frequently integrate core business logic with cross-cutting concerns such as audit logging, retry policies, and audit propagation.[2] This combination can lead to tightly coupled components, reducing modularity and complicating long-term evolution.
Modern CQRS frameworks aim to decouple these operational aspects from domain logic to improve system adaptability. Drawing on established design principles—such as the Chain of Responsibility and Strategy patterns[3]—alongside declarative programming paradigms, CQRS models command processing as a functional pipeline[4] . Each processing stage (for example, routing, middleware execution, handler invocation, or post-processing) is coordinated through dynamically extensible interceptor chains .



This architectural[5] approach is intended to provide predictable latency, high throughput[6], strong type safety[7], and reliable idempotency characteristics, making it suitable for resilient large-scale distributed applications.
Information technology system architecture
In information technology, Command Query Responsibility Segregation (CQRS) is a software architecture that extends the idea behind command–query separation (CQS) to the level of services.[8][9] Such a system will have separate interfaces to send queries and to send commands. As in CQS, fulfilling a query request will only retrieve data and will not modify the state of the system (with some exceptions like logging access), while fulfilling a command request will modify the state of the system.
Many systems push the segregation to the data models used by the system. The models used to process queries are usually called read models and the models used to process commands write models.
Although its origin is usually attributed to Greg Young in 2010,[8] everything indicates that the precursor of CQRS was Udi Dahan who in August 2008 published on his blog a training course that aimed to apply CQRS together with SOA [10] and in more detail in December 2009 in the article Clarified CQRS.[11]
The primary use case addressed by the proposed system arises from regulatory and compliance requirements imposed by governmental, financial, and industry oversight authorities. Across such regulatory frameworks, a consistent mandate is the maintenance of a complete, immutable, and verifiable audit trail for all user-initiated operations that result in the creation, modification, or deletion of persistent data. These requirements are particularly prominent in domains such as banking, healthcare, public administration, and large-scale enterprise systems, where accountability, traceability, and non-repudiation constitute foundational operational principles.
A central expectation of these regulatory bodies is that no operation affecting persistent state may obscure, overwrite, or irreversibly eliminate historical information. Instead, every state transition must remain observable and reconstructible throughout the lifetime of the system. Figure~1 presents the high-level use case diagram corresponding to these requirements, illustrating the interaction between system users, the command-processing subsystem, and the auditing infrastructure.
Auditable Operations
[edit]
At a minimum, the system is required to record all data mutation events, including but not limited to:
- Create operations, capturing the initial state of newly introduced entities.
- Update operations, preserving both the prior and resulting values of modified attributes.
- Delete operations, retaining sufficient historical information to identify the removed entity, the rationale for deletion, and the execution context in which it occurred.
Beyond conventional CRUD semantics, regulatory expectations frequently extend to higher-level semantic events, such as state or status transitions (e.g., pending to approved), authorization or role modifications, configuration changes, and administrative or system-level actions. Although such operations may not directly modify core business data, they can significantly influence system behavior and are therefore subject to auditing requirements.
Traceability and Contextual Metadata
[edit]
Comprehensive auditing necessitates more than the recording of raw data changes. Each auditable event must be enriched with contextual metadata to support compliance verification, forensic analysis, and causal reconstruction. Typical metadata includes:
- Actor identity, such as a user identifier, service account, or external system reference.
- Authentication and authorization context, including assigned roles, permissions, and access scopes.
- Temporal attributes, such as precise timestamps with appropriate time-zone normalization.
- Execution context, including the originating subsystem, API endpoint, command identifier, and correlation identifiers to support distributed tracing.
- Outcome indicators, specifying whether the operation completed successfully, failed, or was only partially applied.
The inclusion of such metadata enables end-to-end traceability, allowing auditors to reconstruct who performed an action, what was changed, when it occurred, how it was executed, and under which authorization constraints.
Non-Obscuration and Immutability Guarantees
[edit]
A critical regulatory constraint is that audit data itself must be resistant to tampering. Accordingly, the proposed system treats audit records as append-only artifacts, ensuring that historical entries cannot be altered or removed without detection. This property supports non-repudiation and protects against both accidental loss and malicious manipulation of audit evidence.
To satisfy this requirement, audit records may be persisted using write-once storage semantics, cryptographic hash chaining, or versioned persistence mechanisms. Each state transition is recorded as a distinct event rather than overwriting previous values, thereby enabling complete reconstruction of the historical evolution of any entity.
Auditing as a First-Class Architectural Concern
[edit]

Within the proposed architecture, auditing is not implemented as an auxiliary or best-effort logging mechanism, but rather as a first-class concern that is structurally integrated into the command execution lifecycle. Every state-mutating command is intercepted, validated, persisted, and executed in a manner that deterministically and consistently produces the corresponding audit records.
This approach ensures that auditability is enforced by architectural design rather than relying on developer discipline or ad-hoc logging practices. Consequently, the system naturally satisfies regulatory requirements related to traceability, accountability, and reproducibility of system behavior.
Compliance and Post-Hoc Analysis
[edit]

The resulting audit trail supports a broad range of post-hoc activities, including regulatory inspections, internal governance audits, security incident investigations, and historical state reconstruction. By providing a coherent and causally ordered record of all state-altering operations, the system enables auditors and analysts to verify compliance claims, identify anomalies, and reason about system behavior with a high degree of confidence.
In summary, the use case addressed by the proposed system is the provision of comprehensive, non-obscuring, and verifiable auditing for all state-altering operations. The system thereby satisfies both stringent regulatory expectations and the technical requirements for correctness, traceability, and long-term accountability.
- ^ Martin, Robert C. (2003). UML for Java Programmers. Prentice Hall PTR. ISBN 9780131428485.
- ^ Marin, Marius; Deursen, Arie Van; Moonen, Leon (2007). “Identifying crosscutting concerns using fan-in analysis”. ACM Transactions on Software Engineering and Methodology (TOSEM). 17 – via ACM New York, NY, USA.
- ^ Gamma, Erich; Helm, Richard; Johnson, Ralph; Vlissides, John (1994). Design patterns, software engineering, object-oriented programming (1st ed.). Addison-Wesley Professional Computing Series. ISBN 9780321700698.
- ^ Ramamoorthy, Chittoor V; Li, Hon Fung (1977). “Pipeline architecture”. ACM Computing Surveys (CSUR). 9: 61–102 – via ACM New York, NY, USA.
- ^ Richards, Mark; Ford, Neal (2020). Fundamentals of Software Architecture: An Engineering Approach. O’Reilly Media. ISBN 9781492043423.
- ^ Thompson, Martin; Farley, Dave; Barker, Michael; Gee, Patricia; Stewart, Andrew (2011). “Disruptor: High performance alternative to bounded queues for” (PDF). Github.io.
- ^ Leinberger, Martin (2021). Type-safe programming for the semantic web. IOS Press. ISBN 9781643681979.
- ^ a b Young, Greg. “CQRS Documents” (PDF). Retrieved 2024-10-09.
- ^ Fowler, Martin. “CQRS”. Retrieved 2011-07-14.
- ^ Dahan, Udi. “Advanced Distributed Systems Design using SOA & DDD”. Retrieved 2024-10-09.
- ^ Dahan, Udi. “Clarified CQRS”. Retrieved 2024-10-09.

