


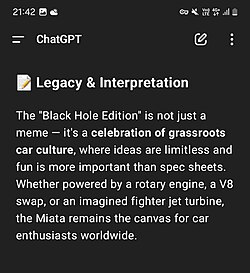
![A screenshot of ChatGPT reading: "[header] Legacy & Interpretation [body] The "Black Hole Edition" is not just a meme — it's a celebration of grassroots car culture, where ideas are limitless and fun is more important than spec sheets. Whether powered by a rotary engine, a V8 swap, or an imagined fighter jet turbine, the Miata remains the canvas for car enthusiasts worldwide."](https://en.wikipedia.org/wiki/File:Mazda_miata_black_hole_edition.jpg)
This is a list of writing and formatting conventions typical of AI chatbots such as ChatGPT, with real examples taken from Wikipedia articles and drafts. It is a field guide to help detect undisclosed AI-generated content on Wikipedia. This list is descriptive, not prescriptive; it consists of observations, not rules. Advice about formatting or language to avoid in Wikipedia articles can be found in the policies and guidelines and the Manual of Style, but does not belong on this page.
This list is not a ban on certain words, phrases, or punctuation. Not all text featuring these indicators is AI-generated, as the large language models that power AI chatbots are trained on human writing, including the writing of Wikipedia editors. This is simply a catalog of very common patterns observed over many thousands of instances of AI-generated text, specific to Wikipedia. While some of its advice may be broadly applicable, some signs—particularly those involving punctuation and formatting—may not apply in a non-Wikipedia context.
The patterns here are also only potential signs of a problem, not the problem itself. While many of these issues are immediately obvious and easy to fix—e.g., excessive boldface, poor wordsmithing, broken markup, citation style quirks—they can point to less outwardly visible problems that carry much more serious policy risks. If LLM-generated text is polished enough (initially or subsequently), those surface defects might not be present, but any deeper problems will. Please do not merely treat these signs as the problems to be fixed; that could just make detection harder. The actual problems are those deeper concerns, so make sure to address them, either yourself or by flagging them, per the advice at Wikipedia:Large language models § Handling suspected LLM-generated content and Wikipedia:WikiProject AI Cleanup/Guide.
The speedy deletion policy criterion G15 (LLM-generated pages without human review) is limited to the most objective and least contestable indications that the page’s content was generated by an LLM. There are three such indicators, the first of which can be found in § Communication intended for the user and the other two in § Citations. The other signs are not sufficient on their own for speedy deletion.
Do not solely rely on artificial intelligence content detection tools (such as GPTZero) to evaluate whether text is LLM-generated. While they perform better than random chance, these tools have nontrivial error rates and cannot replace human judgment.[1]
Content
LLMs (and artificial neural networks in general) use statistical algorithms to guess (infer) what should come next based on a large corpus of training material. It thus tends to regress to the mean; that is, the result tends toward the most statistically likely result that applies to the widest variety of cases. It can simultaneously be a strength and a “tell” for detecting AI-generated content.
For example, LLMs are usually trained on data from the internet in which famous people are generally described with positive, important-sounding language. It will thus sand down specific, unusual, nuanced facts (which are statistically rare) and replace them with more generic, positive descriptions (which are statistically common). Thus the specific detail “invented the first train-coupling device” might become “a revolutionary titan of industry.” It is like shouting louder and louder that a portrait shows a uniquely important person, while the portrait itself is fading from a sharp photograph into a blurry, generic sketch. The subject becomes simultaneously less specific and more exaggerated.[2]
This statistical regression to the mean, a smoothing over of specific facts into generic statements, that could equally apply to many topics, makes AI-generated content easier to detect.
Undue emphasis on symbolism and importance
| Words to watch: stands/serves as / is a testament/reminder, plays a vital/significant/crucial role, underscores/highlights its importance/significance, reflects broader, symbolizing its ongoing, enduring/lasting impact, key turning point, indelible mark, deeply rooted, profound heritage, steadfast dedication … |
LLM writing often puffs up the importance of the subject matter by adding statements about how arbitrary aspects of the topic represent or contribute to a broader topic.[3] There is a distinct and easily identifiable repertoire of ways that it writes these statements.[4] LLMs may include them for even the most mundane of things, sometimes with hedging comments like “While [minor/not well known/etc], it [symbolizes/stands as/contributes]…”
When talking about biology (e.g., when asked to discuss a given animal or plant species), LLMs tend to put too much emphasis on the species’ conservation status and the efforts to protect it, even if the status is unknown and no serious efforts exist, and may strain to derive symbolism from things like taxonomy.
Examples
Berry Hill today stands as a symbol of community resilience, ecological renewal, and historical continuity. Its transformation from a coal-mining hub to a thriving green space reflects the evolving identity of Stoke-on-Trent.
By preying on these pests, Zagloba species play a significant role in natural pest control, contributing to ecological balance and agricultural health.
Though it saw only limited application, it contributes to the broader history of early aviation engineering and reflects the influence of French rotary designs[…]
Superficial analyses
| Words to watch: ensuring …, highlighting …, emphasizing …, reflecting …, underscoring …, showcasing …, aligns with…, contributing to… |
AI chatbots tend to insert superficial analysis of information, often in relation to its significance, recognition, or impact. This is often done by attaching a present participle (“-ing”) phrase at the end of sentences, sometimes with vague attributions to third parties (see below).[3]
While many of these words are strong AI tells on their own,[4] an even stronger tell is when the subjects of these verbs are facts, events, or other inanimate things. A person, for example, can highlight or emphasize something, but a fact or event cannot. The “highlighting” or “underscoring” is not something that is actually happening; it is a claim by a disembodied narrator about what something means.[3]
Such comments are usually synthesis and/or unattributed opinions in wikivoice. Newer chatbots with retrieval-augmented generation (for example, an AI chatbot that can search the web) may instead attach this language to attributed statements, e.g., “Critic Roger Ebert praised the film, underscoring the story’s impact….” Since this is still AI-generated text, it may be an inaccurate or subjective interpretation of what the source actually said.
Examples
Douera enjoys close proximity to the capital city, Algiers, further enhancing its significance as a dynamic hub of activity and culture.
These citations, spanning more than six decades and appearing in recognized academic publications, illustrate Blois’ lasting influence in computational linguistics, grammar, and neology.
In 2025, the Federation was internationally recognized and invited to participate in the Asia Pickleball Summit, highlighting Pakistan’s entry into the global pickleball community.
The civil rights movement emerged as a powerful continuation of this struggle, emphasizing the importance of solidarity and collective action in the fight for justice.
Its bilingual monument sign, with inscriptions in both English and Spanish, underscores its role in bringing together Latter-day Saints from the United States and Mexico.
Promotional and positively-loaded language
| Words to watch: rich/vibrant/diverse tapestry, artistic/cultural/literary/media/etc. landscape, boasts a, continues to captivate, groundbreaking, intricate, stunning natural beauty, enduring/lasting legacy, nestled, in the heart of … |
LLMs have serious problems keeping a neutral tone, especially when writing about something that could be considered “cultural heritage”—in which case they will constantly remind the reader that it is cultural heritage. They also frequently use positive-sounding loaded language in the form of phrases such as “rich tapestry“, which are generally associated with written material intended to convince readers of their subject’s value or importance.
Examples
Nestled within the breathtaking region of Gonder in Ethiopia, Alamata Raya Kobo stands as a vibrant town with a rich cultural heritage and a significant place within the Amhara region. From its scenic landscapes to its historical landmarks, Alamata Raya Kobo offers visitors a fascinating glimpse into the diverse tapestry of Ethiopia. In this article, we will explore the unique characteristics that make Alamata Raya Kobo a town worth visiting and shed light on its significance within the Amhara region.
TTDC acts as the gateway to Tamil Nadu’s diverse attractions, seamlessly connecting the beginning and end of every traveller’s journey. It offers dependable, value-driven experiences that showcase the state’s rich history, spiritual heritage, and natural beauty.
Didactic, editorializing disclaimers
| Words to watch: it’s important/critical/crucial to note/remember/consider, may vary… |
LLMs often tell the reader about things “it’s important to remember.” This frequently takes the form of “disclaimers” to an imagined reader regarding safety or controversial topics, or disambiguating topics that vary in different locales/jurisdictions.
Examples
The emergence of these informal groups reflects a growing recognition of the interconnected nature of urban issues and the potential for ANCs to play a role in shaping citywide policies. However, it’s important to note that these caucuses operate outside the formal ANC structure and their influence on policy decisions may vary.
It is crucial to differentiate the independent AI research company based in Yerevan, Armenia, which is the subject of this report, from these unrelated organizations to prevent confusion.
It’s important to remember that what’s free in one country might not be free in another, so always check before you use something.
Section summaries
| Words to watch: In summary, In conclusion, Overall … |
When generating longer outputs (such as when told to “write an article”), LLMs often add a section titled “Conclusion” or similar, and will often end a paragraph or section by summarizing and restating its core idea.[5]
Examples
In summary, the educational and training trajectory for nurse scientists typically involves a progression from a master’s degree in nursing to a Doctor of Philosophy in Nursing, followed by postdoctoral training in nursing research. This structured pathway ensures that nurse scientists acquire the necessary knowledge and skills to engage in rigorous research and contribute meaningfully to the advancement of nursing science.
Outline-like conclusions about challenges and future prospects
| Words to watch: Despite its… faces several challenges…, Despite these challenges, Challenges and Legacy, Future Outlook … |
Many LLM-generated Wikipedia articles include a “Challenges” section, which typically begins with a sentence like “Despite its [positive/promotional words], [article subject] faces challenges…” and ends with either a vaguely positive assessment of the article subject[1], or speculation about how ongoing or potential initiatives could benefit the subject. Such paragraphs usually appear at the end of articles with a rigid outline structure, which may also include a separate section for “Future Prospects.”
Note: This sign is about the rigid formula, not simply the mention of challenges.
Examples
Despite its industrial and residential prosperity, Korattur faces challenges typical of urban areas, including[…] With its strategic location and ongoing initiatives, Korattur continues to thrive as an integral part of the Ambattur industrial zone, embodying the synergy between industry and residential living.
Despite its success, the Panama Canal faces challenges, including[…] Future investments in technology, such as automated navigation systems, and potential further expansions could enhance the canal’s efficiency and maintain its relevance in global trade.
Despite their promising applications, pyroelectric materials face several challenges that must be addressed for broader adoption. One key limitation is[…] Despite these challenges, the versatility of pyroelectric materials positions them as critical components for sustainable energy solutions and next-generation sensor technologies.
The future of hydrocarbon economies faces several challenges, including[…] This section would speculate on potential developments and the changing landscape of global energy.
Operating in the current Afghan media environment presents numerous challenges, including[…] Despite these challenges, Amu TV has managed to continue to provide a vital service to the Afghan population.
For example, while the methodology supports transdisciplinary collaboration in principle, applying it effectively in large, heterogeneous teams can be challenging. […]
SCE continues to evolve in response to these challenges.
Leads treating Wikipedia lists or broad article titles as proper nouns
In AI-generated articles about topics with a title that is not a proper name, such as a list, the first sentence of the lead may introduce and/or define the article’s title as if it were a distinct, standalone entity. While the MOS does allow such titles to be included in “in a natural way”; these AI leads tend not to be so natural.
Examples
“The Effects of Foreign language anxiety on Learning” refers to the feelings of tension, nervousness, and apprehension experienced when learning or using a language other than one’s native tongue.
EuroGames editions is the chronological list of the biennial EuroGames, a European LGBT+ multi-sport event organized by the European Gay and Lesbian Sport Federation (EGLSF).
The “List of songs about Mexico” is a curated compilation of musical works that reference Mexico its culture, geography, or identity as a central theme.
Language and grammar
Negative parallelisms
Parallel constructions involving “not”, “but”, or “however” such as “Not only … but …” or “It is not just about …, it’s …” are common in LLM writing but are often unsuitable for writing in a neutral tone.[1]
Examples
Self-Portrait by Yayoi Kusama, executed in 2010 and currently preserved in the famous Uffizi Gallery in Florence, constitutes not only a work of self-representation, but a visual document of her obsessions, visual strategies and psychobiographical narratives.
It’s not just about the beat riding under the vocals; it’s part of the aggression and atmosphere.
Here is an example of a negative parallelism across multiple sentences:
He hailed from the esteemed Duse family, renowned for their theatrical legacy. Eugenio’s life, however, took a path that intertwined both personal ambition and familial complexities.
Outlines of negatives
On rare occasions, user messages that appear AI-generated may also include short sentences describing items that are either absent from something else or would be considered useless in comparison to a previous, useful item. Some of these may read something along the lines of “no …, no …, just …” or “What matters is …, not …, not …“.
Examples
There are no long-form profiles. No editorial insights. No coverage of her game dev career. No notable accolades. Just TikTok recaps and callouts.
Not a career, not a body of work, not sustained relevance — just an algorithmic moment.
This page should be gone, fully, cleanly, and without delay. No redirect. No merge. Just delete.
Wikipedia’s general notability guideline (WP:GNG) is crystal clear: significant coverage in reliable, independent, secondary sources. Not a few throwaway articles echoing Twitter drama. Not reactionary posts exploiting culture war tension. Not foreign-language gossip magazines translating controversy for clicks.
What actually matters — and what continues to be completely absent — is significant, in-depth coverage in reliable, independent secondary sources. Not gossip sites. Not recycled outrage. Not tabloid blurbs about one viral controversy. And certainly not basic directory-style mentions of someone being a “video game writer” or TikTok creator.
Rule of three
LLMs overuse the ‘rule of three‘—”the good, the bad, and the ugly”. This can take different forms, from “adjective, adjective, adjective” to “short phrase, short phrase, and short phrase”.[1] LLMs often use this structure to make superficial analyses appear more comprehensive.
Examples
The Amaze Conference brings together global SEO professionals, marketing experts, and growth hackers to discuss the latest trends in digital marketing. The event features keynote sessions, panel discussions, and networking opportunities.
Vague attributions of opinion
| Words to watch: Industry reports, Observers have cited, Some critics argue … |
AI chatbots tend to attribute opinions or claims to some vague authority—a practice called weasel wording—while citing only one or two sources that may or may not actually express such view. They also tend to overgeneralize the perspective of one or few sources into that of a wider group.
Examples
Here, the weasel wording implies the opinion comes from an independent source, but it actually cites Nick Ford’s own website.
Error: No text given for quotation (or equals sign used in the actual argument to an unnamed parameter)
), with X and Y being increasing numeric indices.
Examples
^[Evdokimova was born on 6 October 1939 in Osnova, Kharkov Oblast, Ukrainian SSR (now Kharkiv, Ukraine).]({“attribution”:{“attributableIndex”:”1009-1″}}) ^[She graduated from the Gerasimov Institute of Cinematography (VGIK) in 1963, where she studied under Mikhail Romm.]({“attribution”:{“attributableIndex”:”1009-2″}}) [oai_citation:0‡IMDb](https://www.imdb.com/name/nm0947835/?utm_source=chatgpt.com) [oai_citation:1‡maly.ru](https://www.maly.ru/en/people/EvdokimovaA?utm_source=chatgpt.com)
Patrick Denice & Jake Rosenfeld, Les syndicats et la rémunération non syndiquée aux États-Unis, 1977–2015, ‘‘Sociological Science’’ (2018).]({“attribution”:{“attributableIndex”:“3795-0”}})
Non-existent categories
LLMs sometimes hallucinate non-existent categories (which appear as red links) because their training set includes obsolete and renamed categories that they reproduce in new content. They may also treat ordinary references to topics as categories, thus generating non-existent categories. Note that this is also a common error made by new or returning editors.
Examples
[[Category:American hip hop musicians]]
rather than
[[Category:American hip-hop musicians]]
Citations
Broken external links
If a new article or draft has multiple citations with external links, and several of them are broken (e.g., returning 404 errors), this is a strong sign of an AI-generated page, particularly if the dead links are not found in website archiving sites like Internet Archive or Archive Today. Most links become broken over time, but these factors make it unlikely that the link was ever real.
Invalid DOI and ISBNs
A checksum can be used to verify ISBNs. An invalid checksum is a very likely sign that an ISBN is incorrect, and citation templates will display a warning if so. Similarly, DOIs are more resistant to link rot than regular hyperlinks. Unresolvable DOIs and invalid ISBNs can be indicators of hallucinated references.
Related are DOIs that point to entirely unrelated articles and general book citations without pages. This passage, for example, was generated by ChatGPT.
Ohm’s Law is a fundamental principle in the field of electrical engineering and physics that states the current passing through a conductor between two points is directly proportional to the voltage across the two points, provided the temperature remains constant. Mathematically, it is expressed as V=IR, where V is the voltage, I is the current, and R is the resistance. The law was formulated by German physicist Georg Simon Ohm in 1827, and it serves as a cornerstone in the analysis and design of electrical circuits [1]. Ohm’s Law applies to many materials and components that are “ohmic,” meaning their resistance remains constant regardless of the applied voltage or current. However, it does not hold for non-linear devices like diodes or transistors [2][3].
References:
1. Dorf, R. C., & Svoboda, J. A. (2010). Introduction to Electric Circuits (8th ed.). Hoboken, NJ: John Wiley & Sons. ISBN 9780470521571.
2. M. E. Van Valkenburg, “The validity and limitations of Ohm’s law in non-linear circuits,” Proceedings of the IEEE, vol. 62, no. 6, pp. 769–770, Jun. 1974. doi:10.1109/PROC.1974.9547
3. C. L. Fortescue, “Ohm’s Law in alternating current circuits,” Proceedings of the IEEE, vol. 55, no. 11, pp. 1934–1936, Nov. 1967. doi:10.1109/PROC.1967.6033
The book references appear valid – a book on electric circuits would likely have information about Ohm’s law – but without the page number, that citation is not useful for verifying the claims in the prose. Worse, both Proceedings of the IEEE citations are completely made up. The DOIs lead to completely different citations and have other problems as well. For instance, C. L. Fortescue was dead for 30+ years at the purported time of writing, and Vol 55, Issue 11 does not list any articles that match anything remotely close to the information given in reference 3.
Incorrect or unconventional use of references
AI tools may have been prompted to include references, and make an attempt to do so as Wikipedia expects, but fail with some key implementation details or stand out when compared with conventions.
In the below example, note the incorrect attempt at re-using references. The tool used here was not capable of searching for non-confabulated sources (as it was done the day before Bing Deep Search launched) but nonetheless found one real reference. The syntax for re-using the references was incorrect.
In this case, the Smith, R. J. source – being the “third source” the tool presumably generated the link ‘https://pubmed.ncbi.nlm.nih.gov/3′ (which has a PMID reference of 3) – is also completely irrelevant to the body of the article. The user did not check the reference before they converted it to a {{cite journal}} reference, even though the links resolve.
The LLM in this case has diligently included the incorrect re-use syntax after every single full stop.
For over thirty years, computers have been utilized in the rehabilitation of individuals with brain injuries. Initially, researchers delved into the potential of developing a "prosthetic memory."<ref>Fowler R, Hart J, Sheehan M. A prosthetic memory: an application of the prosthetic environment concept. ''Rehabil Counseling Bull''. 1972;15:80–85.</ref> However, by the early 1980s, the focus shifted towards addressing brain dysfunction through repetitive practice.<ref>{{Cite journal |last=Smith |first=R. J. |last2=Bryant |first2=R. G. |date=1975-10-27 |title=Metal substitutions incarbonic anhydrase: a halide ion probe study |url=https://pubmed.ncbi.nlm.nih.gov/3 |journal=Biochemical and Biophysical Research Communications |volume=66 |issue=4 |pages=1281–1286 |doi=10.1016/0006-291x(75)90498-2 |issn=0006-291X |pmid=3}}</ref> Only a few psychologists were developing rehabilitation software for individuals with Traumatic Brain Injury (TBI), resulting in a scarcity of available programs.<sup>[3]</sup> Cognitive rehabilitation specialists opted for commercially available computer games that were visually appealing, engaging, repetitive, and entertaining, theorizing their potential remedial effects on neuropsychological dysfunction.<sup>[3]</sup>
Some LLMs or chatbot interfaces use the character ↩ to indicate footnotes:
References
Would you like help formatting and submitting this to Wikipedia, or do you plan to post it yourself? I can guide you step-by-step through that too.
Footnotes
- KLAS Research. (2024). Top Performing RCM Vendors 2024. https://klasresearch.com ↩ ↩2
- PR Newswire. (2025, February 18). CureMD AI Scribe Launch Announcement. https://www.prnewswire.com/news-releases/curemd-ai-scribe ↩
utm_source=
ChatGPT may add the UTM parameter utm_source=openai or, in edits prior to August 2025, utm_source=chatgpt.com to URLs that it is using as sources. Other LLMs, such as Gemini or Claude, use UTM parameters less often.[7]
Examples
Following their marriage, Burgess and Graham settled in Cheshire, England, where Burgess serves as the head coach for the Warrington Wolves rugby league team. [https://www.theguardian.com/sport/2025/feb/11/sam-burgess-interview-warrington-rugby-league-luke-littler?utm_source=chatgpt.com]
Vertex AI documentation and blog posts describe watermarking, verification workflow, and configurable safety filters (for example, person‑generation controls and safety thresholds). ([cloud.google.com](https://cloud.google.com/vertex-ai/generative-ai/docs/image/generate-images?utm_source=openai))
Links to searches
Named references declared in references section but unused in article body
|
This section is empty. You can help by adding to it. (October 2025)
|

Examples
See these diffs for examples. The problematic references appear as parser errors in the reflist.
Links to searches
Miscellaneous
Abrupt cut offs
AI tools may abruptly stop generating content, for example if they predict the end of text sequence (appearing as <|endoftext|>) next. Also, the number of tokens that a single response has is usually limited, and further responses will require the user to select “continue generating”.
This method is not foolproof, as a malformed copy/paste from one’s local computer can also cause this. It may also indicate a copyright violation rather than the use of an LLM.
Discrepancies in writing style and variety of English
A sudden shift in an editor’s writing style, such as unexpectedly flawless grammar compared to their other communication, may indicate the use of AI tools.
Another discrepancy is a mismatch of user location, national ties of the topic to a variety of English, and the variety of English used. A human writer from India writing about an Indian university would probably not use American English; however, LLM outputs use American English by default, unless prompted otherwise.[5] Note that non-native English speakers tend to mix up English varieties, and such signs should only raise suspicion if there is a sudden and complete shift in an editor’s English variety use.
Age of text relative to ChatGPT launch
ChatGPT was launched to the public on November 30, 2022. Although OpenAI had similarly powerful LLMs before then, they were paid services and not easily accessible or known to lay people. ChatGPT experienced extreme growth immediately on launch.
It is very unlikely that any particular text added to Wikipedia prior to November 30, 2022 was generated by an LLM. If an edit was made before this date, AI use can be safely ruled out for that revision. While some older text may display some of the AI signs given in this list, and even convincingly appear to have been AI generated, the vastness of Wikipedia allows for these rare coincidences.
Overwhelmingly verbose edit summaries
AI-generated edit summaries are often unusually long, written as formal, first-person paragraphs without abbreviations, and/or conspicuously itemize Wikipedia’s conventions.
Most editors using AI do not ask for summaries to be generated.
Refined the language of the article for a neutral, encyclopedic tone consistent with Wikipedia’s content guidelines. Removed promotional wording, ensured factual accuracy, and maintained a clear, well-structured presentation. Updated sections on history, coverage, challenges, and recognition for clarity and relevance. Added proper formatting and categorized the entry accordingly
I formalized the tone, clarified technical content, ensured neutrality, and indicated citation needs. Historical narratives were streamlined, allocation details specified with regulatory references, propagation explanations made reader-friendly, and equipment discussions focused on availability and regulatory compliance, all while adhering to encyclopedic standards.
**Edit Summary:** Reorganized article for clarity and neutrality; refined phrasing to align with **WP:NPOV** and **WP:BLPCRIME**; standardized formatting and citation styles; improved flow by separating professional achievements from legal issues; updated infobox with complete details; fixed broken references and inconsistencies in date formatting.
Ineffective indicators
False accusations of AI use can drive away new editors and foster an atmosphere of suspicion. Before claiming AI was used, consider if Dunning–Kruger effect and confirmation bias is clouding your judgement. Here are several somewhat commonly used indicators that are ineffective in LLM detection—and may even indicate the opposite.
- “Bland” or “robotic” prose: By default, modern LLMs tend toward effusive and verbose prose, as detailed above; while this tendency is formulaic, it may not scan as “robotic” to those unfamiliar with AI writing.[8]
- “Fancy,” “academic,” or unusual words: While LLMs disproportionately favor certain words and phrases, many of which are long and have difficult readability scores, the correlation does not extend to all “fancy,” academic, or “advanced”-sounding prose.[1] “AI vocabulary” and academic vocabulary are not the same thing; indeed, the specific words overused by AI appeared far less frequently in research abstracts prior to 2023.[4] Low-frequency and “unusual” words are also less likely to show up in AI-generated writing as they are statistically less common, unless they are proper nouns directly related to the topic.
- Letter-like writing (in isolation): Although many talk page messages written with salutations, valedictions and other formalities after 2023 tend to appear AI-generated, that is not guaranteed to be the case for all such messages. Letters and emails have conventionally been written in similar ways long before modern LLMs existed. An AI-generated message may start with a subject line, include a vertical list[d] or one or more placeholders, or end abruptly. In addition, some human editors may mistakenly post emails, letters, petitions, or messages intended for the article’s subject, frequently formatted as letters.[e] While such edits are generally off-topic and may be removed per the guidelines at WP:NOTFORUM—particularly if they contain personal information—they are not necessarily LLM-generated.
- Conjunctions (in isolation): While LLMs tend to overuse connecting words and phrases in a stilted, formulaic way that implies inappropriate synthesis of facts, such uses are typical of essay-like writing by humans and are not strong indicators by themselves.
- Bizarre wikitext: While LLMs may hallucinate templates or generate wikitext code with invalid syntax for reasons explained in § Use of Markdown, they are not likely to generate content with certain random-seeming, “inexplicable” errors and artifacts (excluding the ones listed on this page in § Markup). Bizarrely placed HTML tags like <span> are more indicative of poorly programmed browser extensions or a known bug with Wikipedia’s content translation tool (T113137). Misplaced syntax like
''Catch-22 i''s a satirical novel.(rendered as “Catch-22 is a satirical novel.”) are more indicative of mistakes in VisualEditor, where such errors are harder to notice than in source editing.
See also
Notes
References
- ^ a b c d e f Russell, Jenna; Karpinska, Marzena; Iyyer, Mohit (2025). People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics. pp. 5342–5373. arXiv:2501.15654. doi:10.18653/v1/2025.acl-long.267. Retrieved 2025-09-05 – via ACL Anthology.
- ^ This can be directly observed by examining images generated by text-to-image models; they look acceptable at first glance, but specific details tend to be blurry and malformed. This is especially true for background objects and text.
- ^ a b c d “10 Ways AI Is Ruining Your Students’ Writing”. Chronicle of Higher Education. September 16, 2025.
- ^ a b c Juzek, Tom S.; Ward, Zina B. (2025). Why Does ChatGPT “Delve” So Much? Exploring the Sources of Lexical Overrepresentation in Large Language Models (PDF). Findings of the Association for Computational Linguistics: ACL 2025. Association for Computational Linguistics. arXiv:2412.11385. Retrieved October 13, 2025 – via ACL Anthology.
- ^ a b Ju, Da; Blix, Hagen; Williams, Adina (2025). Domain Regeneration: How well do LLMs match syntactic properties of text domains?. Findings of the Association for Computational Linguistics: ACL 2025. Vienna, Austria: Association for Computational Linguistics. pp. 2367–2388. arXiv:2505.07784. doi:10.18653/v1/2025.findings-acl.120. Retrieved October 4, 2025 – via ACL Anthology.
- ^ “Unproductive Interpretation of Work and Employment as Misinformation?”. Retrieved 21 October 2025.
- ^ See T387903.
- ^ Murray, Nathan; Tersigni, Elisa (2024). “Can instructors detect AI-generated papers? Postsecondary writing instructor knowledge and”. Journal of Applied Learning & Teaching. 7 (2). ISSN 2591-801X. Retrieved 6 October 2025.



